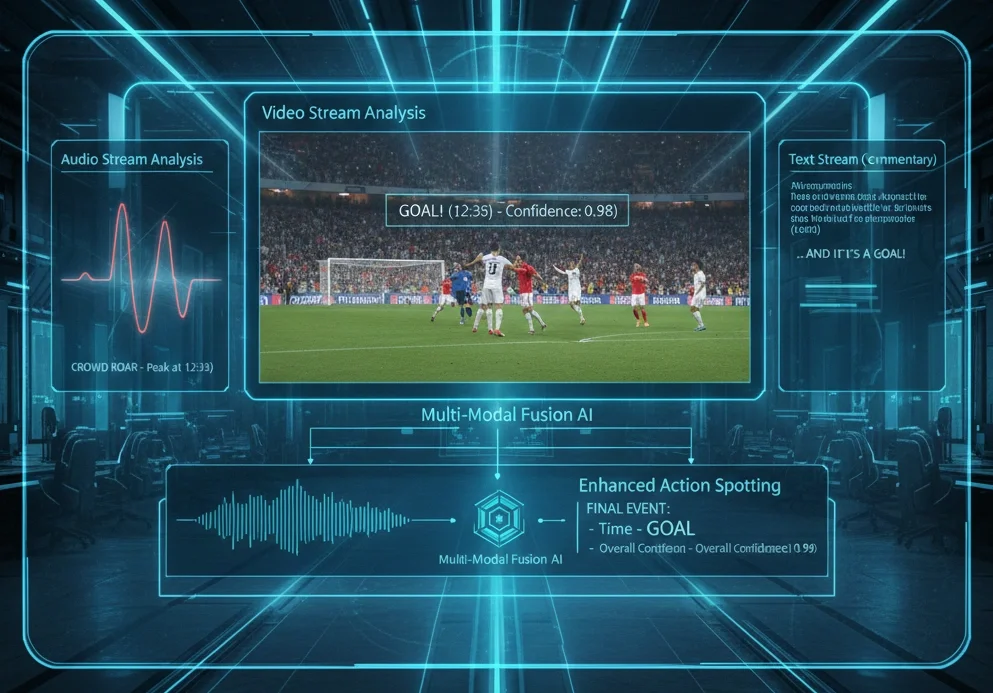
'언제 무슨 일이 일어났는지'를 놓치지 않는 액션 스포팅의 최전선과 Playbox가 얻은 실전 팁
안녕하세요! Playbox에서 인턴으로 참여하고 있는 나카타니 치요입니다. 평소에는 박사 과정에서 사람의 행동 인식에 관한 연구(CVIU2026·CVPR2024·ICCV2023)를 진행하고 있습니다.
이번에는 최근 스포츠 분석 분야에서 뜨거운 관심을 받고 있는 '액션 스포팅(Action Spotting)'에 대해 기술적 배경부터 실용화의 포인트까지 간결하게 설명하겠습니다.
목차
- 액션 스포팅이란?
- SoccerNet at CVSports
- Playbox에서의 액션 스포팅 활용
- 요약 및 향후 전망
1. 액션 스포팅이란?
일반적인 Video Classification이 "이 동영상 전체에서 무슨 일이 일어나고 있는지"를 맞추는 반면, Action Spotting은 "긴 동영상에서 '언제' '어떤 액션'이 일어났는지"를 정확히 검출하는 작업입니다. 스포츠 영상에서는 슛과 같은 액션(이벤트)은 정말 순간적인 사건입니다. 이 "순간의 이벤트"를 시간축에 따라 높은 정확도로 검출하고 타임스탬프를 특정하는 것이 Action Spotting의 목표입니다.
SoccerNet 동영상에서의 액션 스포팅 예시
액션 스포팅은 하이라이트 영상 제작, 전술 분석, 스카우팅을 위한 선수 평가, 팬 참여 유도 등 다양한 분야에 응용 가능합니다.
2. CVSports에서의 액션 스포팅
스포츠 분석을 논할 때 빼놓을 수 없는 것이 SoccerNet이라는 데이터셋과 벤치마크입니다. 컴퓨터 비전 분야 최고봉 국제 학회 중 하나인 CVPR의 워크숍 'CVSports'에서는 이 데이터셋을 활용한 다양한 경연이 개최되고 있습니다. 또한, 올해 6월에 개최되는 CVSports(CVPR2026)에서는 Playbox CEO인 Atom Scott 씨의 초청 강연도 진행됩니다. 기대해 주세요!
2.1 SoccerNet 데이터셋
유럽 주요 리그에서 수집된 500경기 이상의 영상으로 구성되어 있습니다. 최근에는 액션 스포팅 외에도 각 인물의 역할(필드 플레이어, 골키퍼, 심판 등)과 위치 정보 등을 파악하는 상태 인식(GSR)도 전술 분석과 플레이 평가에서 매우 중요한 기술로 연구되고 있습니다. Playbox도 CVSports(CVPR2025)의 GSR 경진대회에 참가하고 있습니다.
2.2 액션 스포팅을 위한 어노테이션
SoccerNet에서는 액션 스포팅을 위해 17종류의 액션 클래스가 검출 대상으로 정의되어 있습니다. 이들 17종류의 액션 클래스가 발생한 타임스탬프가 각 동영상에 어노테이션되어 있습니다. 17개 클래스를 액션의 종류와 검출에 필요한 특징에 주목하여 분류하면 다음과 같습니다.
[슈팅 계열 액션]
- 골(Goal)・골대 안 슛(Shots on target)・골대 밖 슛(Shots off target)
- 중요 특징: "공의 궤적" 및 "골 네트의 움직임"
[킥 계열 액션]
- 간접 프리킥(Indirect free-kick)・직접 프리킥(Direct free-kick)・킥오프(Kick-off)・코너킥(Corner)・클리어(Clearance)・스로인(Throw-in)
- 주요 특징: 「공의 위치」나 「선수들의 진형」
[판정 관련 및 기타]
- 오프사이드(Offside)・페널티(Penalty)・파울(Foul)・옐로 카드(Yellow card)・레드 카드(Red card)・옐로→레드 카드(Yellow->red card)・선수 교체(Substitution)・공 아웃(Ball out of play)
- 주요 특징: "심판의 제스처" · "특정 선수의 상세한 움직임 정보"
2.3 평가 지표
Action Spotting에서는 mAP(mean Average Precision)를 통해 대상 액션이 "언제(타임스탬프)" 발생했는지를 얼마나 정확하게 예측했는지 평가합니다. 예측된 타임스탬프가 정답(Ground Truth)으로부터 일정 시간 내(δ초 이내)에 있으면 정답으로 간주되며, 각 클래스별로 정밀도와 재현율로부터 AP(Average Precision)가 계산됩니다.
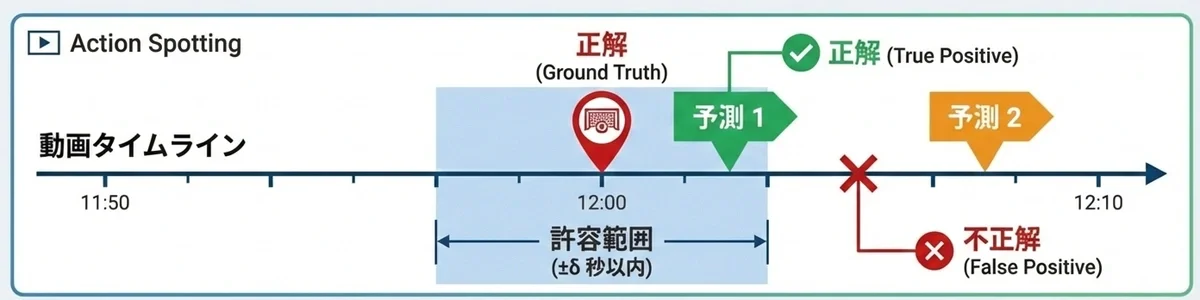
액션 스포팅에서의 검출 결과 성공 여부 판정
2.4 베이스라인 모델
Action Spotting에서 매우 강력한 성능을 발휘하는 모델은 T-DEED: Temporal-Discriminability Enhancer Encoder-Decoder for Precise Event Spotting in Sports Videos입니다. CVsports '24에서 발표된 이 기법은 L 프레임으로 구성된 동영상에서 시계열 특징을 추출하면서 각 프레임에 대해 "액션 발생 여부" 및 "어떤 액션이 발생했는지"를 검출합니다.아래 그림에서도 알 수 있듯이 "액션이 발생하지 않은" 프레임이 방대하게 존재하는 것은 학습 과정의 어려움 중 하나입니다.
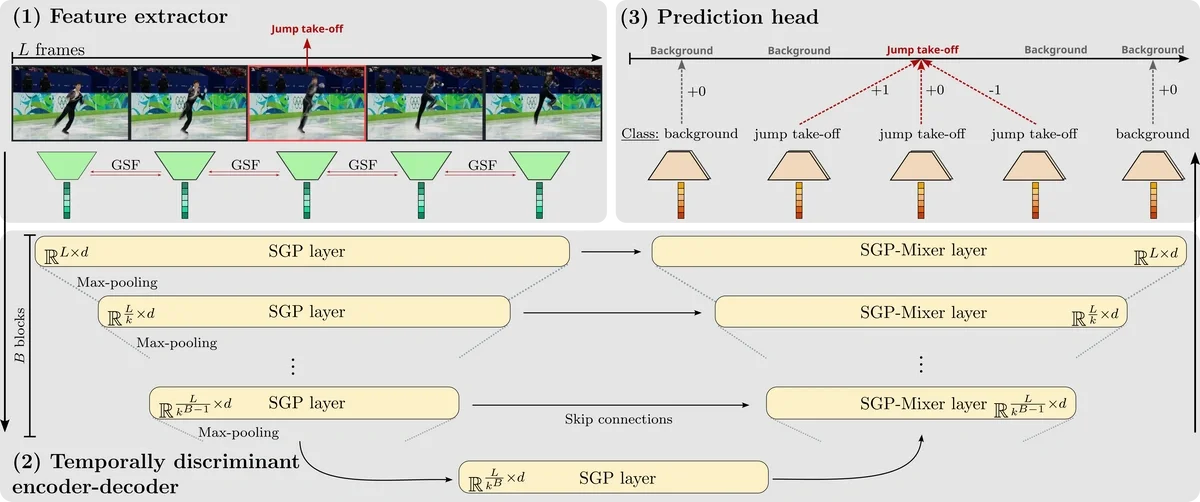
T-DEED 개요도 (https://arturxe2.github.io/projects/T-DEED/)
실제로 이 T-DEED로 SoccerNet의 Action Spotting을 학습한 결과를 보면, mAP가 60-80 근처로 비교적 높은 성능으로 검출이 성공했음을 알 수 있습니다.
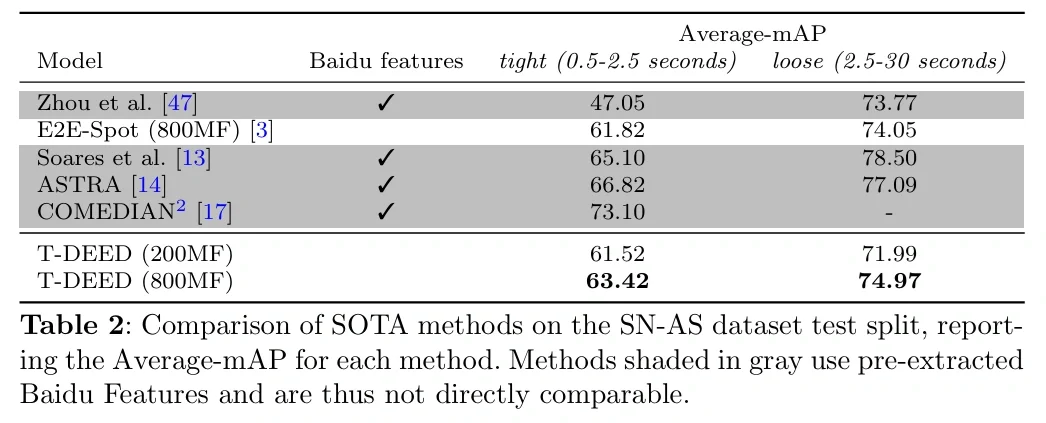
SoccerNet 데이터셋에서의 mAP (https://arturxe2.github.io/projects/T-DEED/)
다만 SoccerNet의 동영상은 방송용 영상이기 때문에 각 동영상 간 촬영 환경이 유사하여 적은 데이터로도 학습이 비교적 용이하다고 생각됩니다. 따라서 다음 섹션에서는 SoccerNet과 다른 다양한 환경에서의 촬영이 예상되는 Playbox camera에서의 실제 학습 사례를 소개합니다.
3. Playbox 카메라에서의 액션 스포팅
Playbox Camera는 다양한 환경에서의 촬영을 가정하고 있어 SoccerNet에 비해 동영상 간 촬영 환경의 차이가 큽니다. 이번에는 이처럼 다양한 촬영 환경에서 촬영된 동영상으로 Action Spotting을 수행하기 위해 필요한 데이터량 등에 대한 조사를 실시했습니다.
3.1 데이터셋 개요
이번에 사용한 데이터셋의 구체적인 내용을 소개합니다.
3.1.1 Playbox Camera 영상 데이터
Playbox Camera로 촬영된 영상은 실제 경기의 생생함을 그대로 담아내며, 경기장 전체나 특정 플레이를 포착하고 있습니다. 아래에 실제 동영상을 보여드립니다.
Playbox camera 촬영 동영상 예시
3.1.2 액션 클래스
이번에는 축구 경기에서 다음과 같은 6가지 클래스를 대상으로 합니다.
| 클래스명 | 내용 |
| ck | 코너킥 |
| kick off | 킥오프 |
| goal | 골 장면 |
| 슛 | 슛 |
| fk | 프리킥 |
| pk | 페널티킥 |
3.1.3 주석 기법
사람의 손에 의한 수동 어노테이션을 실시했습니다. 각 동영상을 프레임 단위로 확인하고, 특정 액션(예: 공을 찬 순간, 골라인을 넘은 순간)이 발생한 타임스탬프를 기록하고 있습니다.
3.1.4 데이터 규모
분석에 사용한 데이터의 총량은 다음과 같습니다.
-
총 동영상 수: 345개
-
주석 단위: 각 동영상 내 상기 6개 클래스의 발생 지점
이러한 데이터 세트를 사용하여 Playbox Camera의 영상에서 자동으로 경기 하이라이트를 추출하거나 통계 데이터를 생성하기 위한 기반을 구축하고 있습니다.
3.2 결과
345개의 동영상을 사용하여 학습을 수행한 결과, "특정 패턴을 가진 플레이에는 매우 강하지만, 갑작스러운 움직임에는 개선의 여지가 있다"는 결과가 나왔습니다. 특히 시작 신호나 세트 플레이는 비교적 높은 정확도로 감지할 수 있습니다.
3.2.1 mAP 결과
먼저, 각 클래스의 mAP를 확인합니다.
| 클래스 | mAP |
| 전체 평균 | 0.43 |
| kick off | 0.71 |
| 슛 | 0.59 |
| ck (코너킥) | 0.51 |
| fk (프리킥) | 0.39 |
| goal | 0.38 |
| pk (페널티 킥) | 0.00 |
3.2.2 결과에서 드러나는 고찰
-
「세트 플레이」는 높은 정확도
kick off(0.71) 및ck(0.51)의 mAP가 높게 나왔습니다. 이는 「선수가 정지한 상태에서 시작」이라는 명확한 패턴이 있어 학습이 용이했기 때문으로 생각됩니다. -
「goal」 판정의 어려움
goal(0.38)은 "슛을 했다"와 "그것이 득점이 되었다"라는 두 사건이 얽힌 복잡한 액션으로 학습이 어려워진 것으로 보입니다.
3.2.3 추론 결과 시각화(동영상)
실제 shot과 ck의 검출 사례를 동영상으로 확인해 보십시오.
Playbox camera 촬영 동영상에서의 shot 검출 결과
Playbox 카메라 촬영 동영상에서의 ck 검출 결과
3.3 상세 분석
3.3.1 데이터량(주석 수)과 mAP
"얼마나 많은 어노테이션을 해야 정확도가 나오나요?"는 가장 많은 질문 중 하나입니다. 결론부터 말하자면, 동영상 수(어노테이션 수)를 늘릴수록 mAP는 향상되지만, 어느 지점에서 포화가 시작됩니다. 아래에 실제 동영상 수와 shot 클래스에서의 mAP를 보여드리지만, 동영상 수가 늘어남에 따라 정확도 향상 효율이 둔화되고 있음을 알 수 있습니다.
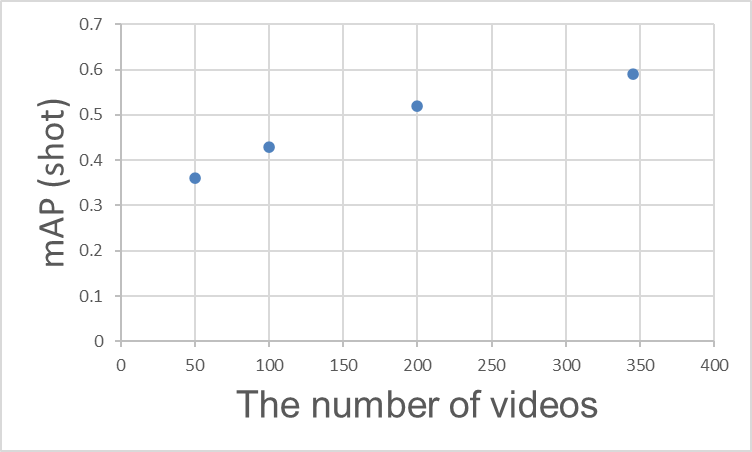
학습 동영상 수와 mAP(shot)의 관계
3.3.2 프레임 수(FPS)와 mAP
액션 스포팅에서는 몇 프레임으로 구성된 동영상을 사용할지가 검출에 중요한 장면 맥락을 이해하는 데 중요합니다. 예를 들어, 골 검출을 위해서는 공이 골망을 흔드는 모습뿐만 아니라 득점 팀이 기뻐하거나 실점 팀이 아쉬워하는 장면 맥락도 보조적으로 활용한 검출이 기대됩니다.
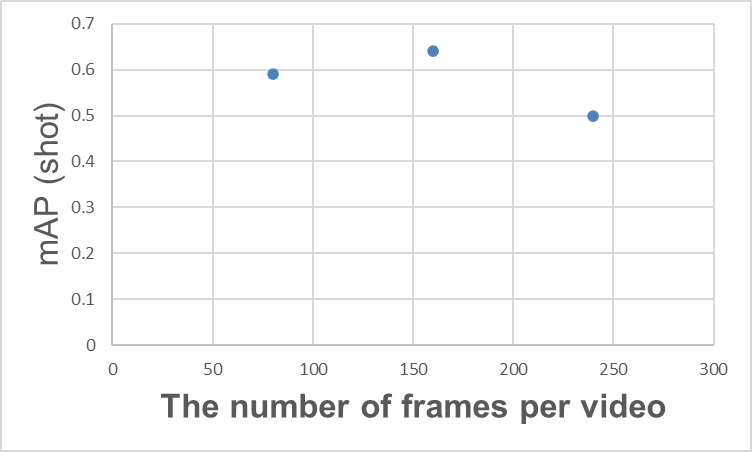
1동영상 프레임 수와 mAP(샷)의 관계성
그렇다면 "동영상 프레임 수만 늘리면 된다"는 결론이 나올 것 같지만, 반드시 그렇지만은 않습니다. 예를 들어, 위 그래프에서 보듯 동영상 프레임 수를 늘리다 보면 어느 시점에서 mAP가 포화 상태에 도달하고, 이후에는 mAP가 하락하는 경우가 있습니다. 이러한 결과는 T-DEED 논문에서도 유사한 결과가 기록되어 있습니다(Table 6 (d)). 그 원인은 다양하게 생각할 수 있지만, 프레임 수가 늘어날수록 얻는 정보는 많아지는 반면 학습이 어려워지는 것이 한 가지 원인으로 생각됩니다.
동영상 프레임 수를 늘리면 추론에 필요한 계산량도 증가하므로, 요구되는 성능이나 추론 속도, 대상 액션의 종류에 따라 동영상 프레임 수를 조정하는 것이 성능 향상에 기여할 것으로 생각됩니다.
3.4 Playbox의 시행착오
3.4.1 T-DEED의 고정 FPS 설정
먼저 "특정 1개 동영상에 대해 과적합(오버핏)이 가능한지"를 검증했습니다. 일반적으로 모델이 올바르게 구성되었다면 소량의 데이터에 대해서는 완벽하게 적합할 수 있어야 합니다. 그러나 결과는 실패였습니다. 하나의 동영상으로만 좁혀도 정확도가 전혀 향상되지 않았습니다. 조사 결과, 의외의 맹점이 드러났습니다.
원인은 TDEED 내부에서 동영상의 FPS(프레임 레이트)가 고정되어 있어 Playbox 동영상이 가진 본래의 FPS와 괴리되어 있었습니다. 시계열 액션 인식에서 시간 흐름(FPS)의 불일치는 치명적입니다. 이 사양을 인지하고 Playbox 동영상 형식에 맞춰 FPS 설정을 적절히 조정하자 학습이 원활히 진행되었습니다."최소한의 단위에서 오버핏을 먼저 확인하라"는 디버깅의 기본 원칙이 결과적으로 근본적인 사양 오류를 발견하는 지름길이 되었습니다.
3.4.2 사전 학습 모델과 데이터 확장의 효과
지견으로서, 정확도 향상을 위해 시도했지만 효과가 없었던 것들도 기록합니다.
-
SoccerNet 사전 학습 모델의 파인 튜닝: Soccernet으로 학습된 모델을 파인 튜닝했지만, 이번 Playbox 동영상에 대해서는 눈에 띄는 정확도 향상은 보이지 않았습니다.
-
데이터 확장(Data Augmentation) 적용: TDEED에서 설정 가능한 데이터 확장을 모두 시도해 보았지만, 이것도 결과에는 거의 영향을 미치지 않았습니다.
4. 요약 및 향후 전망
지금까지 봐 주셔서 감사합니다!
이번 포인트
- Action Spotting은 '언제' '무엇이' 일어났는지를 검출하는 기술입니다.
- SoccerNet은 유명한 방송 영상 데이터셋이며, T-DEED 등 다양한 기법이 제안되었습니다.
- Playbox 카메라로 촬영한 영상에서의 Action Spotting 성능을 검증했습니다.
향후 전망
향후에는 영상뿐만 아니라 음성(환호 소리 크기)이나 텍스트(실황 데이터) 등을 결합한 멀티모달 액션 스포팅을 통해 더욱 높은 성능 향상이 기대됩니다.