Ne manquez pas de découvrir "ce qui s'est passé quand", la ligne de front du repérage des actions et les conseils pratiques de Playbox.
Bonjour ! Je m'appelle Chihiro Nakatani et je suis stagiaire chez Playbox. Je suis actuellement doctorante et je mène des recherches sur la reconnaissance des comportements humains (CVIU2026, CVPR2024, ICCV2023).
Dans cet article, je vais vous présenter de manière concise l'« Action Spotting » (détection d'actions), un domaine qui suscite un vif intérêt dans le domaine de l'analyse sportive ces dernières années, depuis son contexte technique jusqu'à ses applications pratiques.
Table des matières
- Qu'est-ce que l'Action Spotting ?
- SoccerNet chez CVSports
- Utilisation de l'Action Spotting dans Playbox
- Résumé et perspectives d'avenir
1. Qu'est-ce que l'Action Spotting ?
Alors que la classification vidéo classique consiste à déterminer « ce qui se passe dans l'ensemble de la vidéo », l'Action Spotting est une tâche qui consiste à détecter avec précision « quand » et « quelle action » s'est produite dans une longue vidéo. Dans les vidéos sportives, les actions (événements) telles que les tirs ne durent qu'un instant. L'objectif de l'Action Spotting est de détecter ces « événements instantanés » avec une grande précision sur l'axe temporel et d'identifier leur horodatage.
SoccerNet Exemple d'Action Spotting dans une vidéo
Action Spotting peut être appliqué à divers domaines, tels que la création de vidéos de moments forts, l'analyse tactique, l'évaluation des joueurs à des fins de recrutement et l'engagement des fans.
2. Action Spotting chez CVSports
Lorsqu'on parle d'analyse sportive, il est impossible de passer à côté du dataset et du benchmark SoccerNet. Le workshop « CVSports » de la CVPR, l'une des conférences internationales les plus prestigieuses dans le domaine de la vision par ordinateur, organise diverses compétitions utilisant ce dataset. Par ailleurs, lors du CVSports (CVPR2026) qui se tiendra en juin prochain, Atom Scott, PDG de Playbox, donnera une conférence sur invitation. Ne manquez pas cet événement !
2.1 Ensemble de données SoccerNet
Il est composé de plus de 500 matchs filmés dans les principales ligues européennes. Ces dernières années, outre l'Action Spotting, la reconnaissance de l'état (GSR), qui permet de déterminer le rôle de chaque personne (joueur de champ, gardien de but, arbitre, etc.) et sa position, est également considérée comme une technologie très importante pour l'analyse tactique et l'évaluation du jeu. Playbox participe également au concours GSR de CVSports (CVPR2025).
2.2 Annotations pour Action Spotting
SoccerNet définit 17 types d'actions à détecter pour l'Action Spotting. Les timestamps correspondant à ces 17 types d'actions sont annotés dans chaque vidéo. Les 17 types d'actions peuvent être classés comme suit en fonction du type d'action et des caractéristiques nécessaires à leur détection.
[Actions de tir]
- But (Goal)・Tirs cadrés (Shots on target)・Tirs non cadrés (Shots off target)
- Caractéristiques importantes : « trajectoire du ballon » et « mouvement du filet du but »
[Actions de type « coup de pied »]
- Coup franc indirect (Indirect free-kick)・Coup franc direct (Direct free-kick)・Coup d'envoi (Kick-off)・Corner (Corner)・Dégagement (Clearance)・Remise en jeu (Throw-in)
- Caractéristiques importantes : « position du ballon » et « formation des joueurs »
[Décisions de l'arbitre et autres]
- Hors-jeu (Offside) - Pénalité (Penalty) - Faute (Foul) - Carton jaune (Yellow card) - Carton rouge (Red card) - Carton jaune → carton rouge (Yellow->red card) - Remplacement (Substitution) - Ballon hors jeu (Ball out of play)
- Caractéristiques importantes : « gestes de l'arbitre » et « informations détaillées sur les mouvements de certains joueurs ».
2.3 Indicateurs d'évaluation
Action Spotting utilise la mAP (mean Average Precision) pour évaluer la précision avec laquelle l'action cible a été prédite (« quand » (horodatage)). Si l'horodatage prédit se situe dans un certain intervalle de temps (δ secondes) par rapport à la vérité terrain (Ground Truth), il est considéré comme correct, et l'AP (Average Precision) est calculé à partir du taux de conformité et du taux de reproduction pour chaque classe.
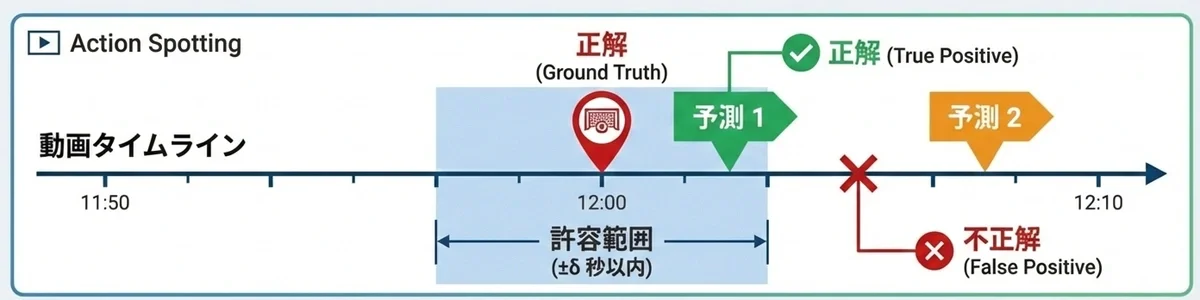
Évaluation de la réussite des résultats de détection dans Action Spotting
2.4 Modèle de référence
T-DEED (Temporal-Discriminability Enhancer Encoder-Decoder for Precise Event Spotting in Sports Videos) est un modèle qui affiche des performances très élevées dans Action Spotting. Cette méthode, présentée lors de la conférence CVsports '24, détecte « si une action se produit ou non » et « quelle action se produit » pour chaque image d'une vidéo composée d'images L, tout en acquérant des caractéristiques chronologiques.Comme le montre le schéma ci-dessous, le nombre considérable d'images « sans action » constitue l'une des difficultés de l'apprentissage.
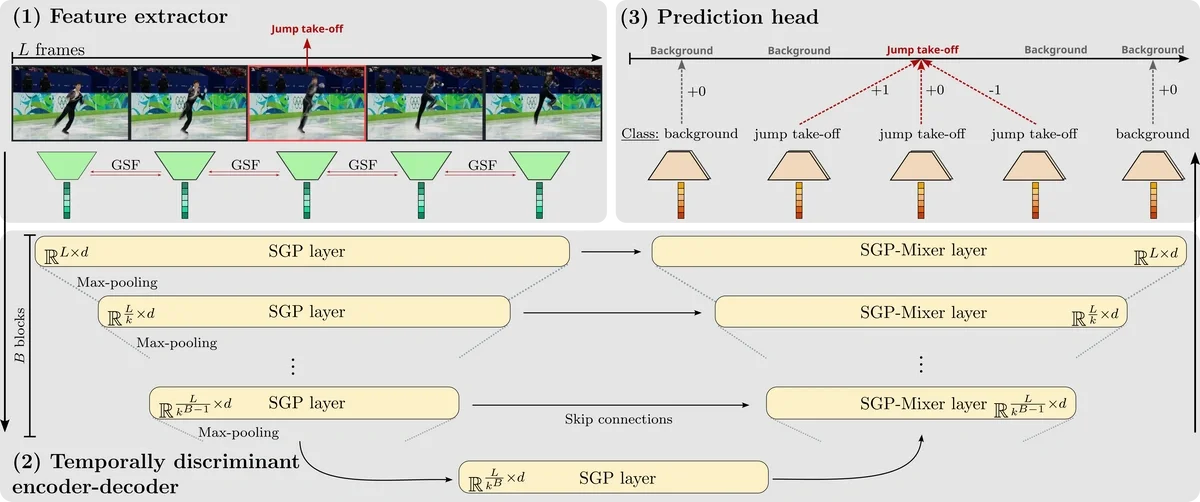
Schéma général du T-DEED (https://arturxe2.github.io/projects/T-DEED/)
Les résultats de l'apprentissage de la détection d'actions dans SoccerNet à l'aide de T-DEED montrent que le mAP se situe entre 60 et 80, ce qui indique que la détection est relativement performante.
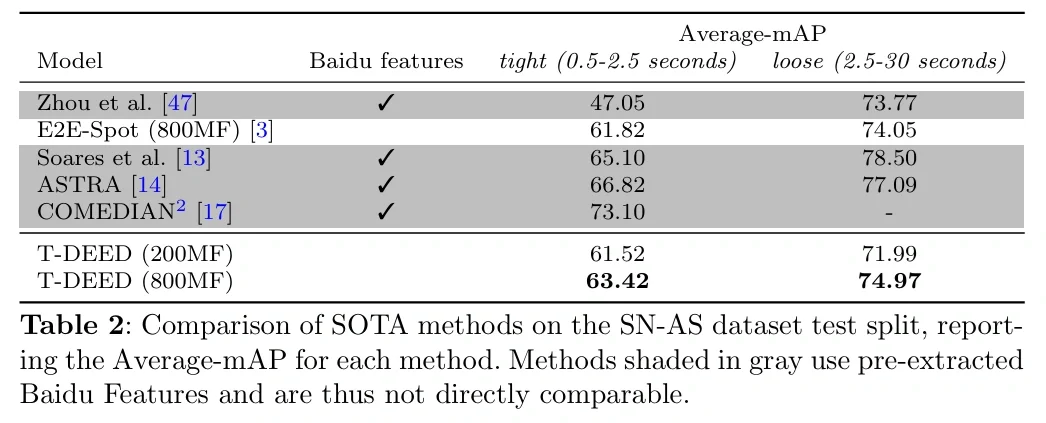
mAP sur le dataset SoccerNet (https://arturxe2.github.io/projects/T-DEED/)
Cependant, les vidéos de SoccerNet étant destinées à la diffusion, les conditions de tournage sont similaires d'une vidéo à l'autre, ce qui facilite l'apprentissage même avec peu de données. Dans la section suivante, nous présenterons donc des exemples d'apprentissage réel avec la caméra Playbox, qui permet de filmer dans des environnements différents de ceux de SoccerNet.
3. Action Spotting avec la caméra Playbox
La caméra Playbox est conçue pour filmer dans divers environnements, et les conditions de tournage varient considérablement d'une vidéo à l'autre par rapport à SoccerNet. Nous avons donc mené une étude sur la quantité de données nécessaires pour effectuer l'Action Spotting à partir de vidéos tournées dans des environnements aussi divers.
3.1 Aperçu du jeu de données
Nous vous présentons ici le contenu spécifique du jeu de données utilisé.
3.1.1 Données vidéo de la caméra Playbox
Les images filmées avec Playbox Camera capturent l'ensemble du terrain et des actions spécifiques tout en conservant le réalisme d'un match réel. Vous trouverez ci-dessous une vidéo réelle.
Exemple de vidéo filmée avec la Playbox Camera
3.1.2 Classes d'actions
Cette fois-ci, nous avons ciblé les 6 classes suivantes dans un match de football.
| Nom de la classe | Contenu |
| ck | Corner |
| Coup d'envoi | Coup d'envoi |
| goal | Scène de but |
| shot | tir |
| fk | coup franc |
| pk | penalty |
3.1.3 Méthode d'annotation
Nous avons procédé à une annotation manuelle. Nous avons visionné chaque vidéo image par image et enregistré les moments précis où certaines actions se sont produites (par exemple, le moment où le ballon a été frappé, le moment où il a franchi la ligne de but).
3.1.4 Volume des données
La quantité totale de données utilisées pour l'analyse est la suivante.
-
Nombre total de vidéos : 345
-
Unités d'annotation : points d'occurrence des 6 classes ci-dessus dans chaque vidéo
Ces ensembles de données nous ont permis de créer une base pour extraire automatiquement les moments forts des matchs à partir des images de la Playbox Camera et pour générer des données statistiques.
3.2 Résultats
Après apprentissage à partir des 345 vidéos, nous avons obtenu les résultats suivants : « très performant pour les actions présentant un schéma spécifique, mais perfectible pour les mouvements imprévisibles ». Les coups d'envoi et les coups de pied arrêtés sont notamment détectés avec une précision relativement élevée.
3.2.1 Résultats mAP
Commençons par vérifier le mAP de chaque classe.
| Classe | mAP |
| Moyenne globale | 0,43 |
| kick off | 0,71 |
| tir | 0,59 |
| ck (Corner Kick) | 0,51 |
| fk (coup franc) | 0,39 |
| goal | 0,38 |
| pk (Penalty Kick) | 0,00 |
3.2.2 Réflexion à partir des résultats
-
Les « coups de pied arrêtés » sont très précis
kick off(0,71) etck(0,51). On peut supposer que ces derniers ont été faciles à apprendre, car ils suivent un schéma clair où « les joueurs commencent à partir d'une position immobile ». -
La difficulté de déterminer un « but »
goal(0,38) est une action complexe impliquant deux événements, à savoir « le tir » et « le but marqué », ce qui a rendu l'apprentissage difficile.
3.2.3 Visualisation des résultats de l'inférence (vidéo)
Veuillez visionner la vidéo pour voir des exemples concrets de détection de tirs et de corners.
Résultats de détection des tirs dans les vidéos filmées par la caméra Playbox
Résultats de détection des ck dans les vidéos filmées par la caméra Playbox
3.3 Analyse détaillée
3.3.1 Volume de données (nombre d'annotations) et mAP
« Combien d'annotations faut-il pour obtenir une bonne précision ? » est l'une des questions les plus fréquemment posées. En conclusion, plus le nombre de vidéos (nombre d'annotations) augmente, plus le mAP s'améliore, mais à partir d'un certain point, la saturation commence. Le tableau ci-dessous montre le nombre réel de vidéos et le mAP dans la classe shot. On constate que l'augmentation du nombre de vidéos ralentit l'amélioration de la précision.
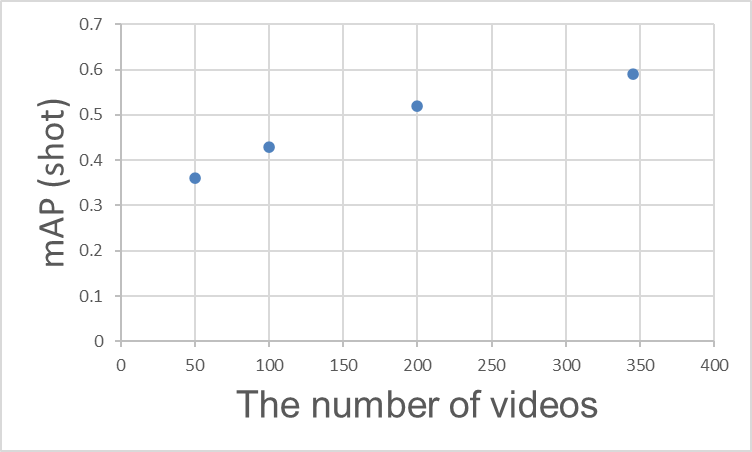
Relation entre le nombre de vidéos d'apprentissage et le mAP (shot)
3.3.2 Nombre d'images par seconde (FPS) et mAP
Dans Action Spotting, le nombre d'images composant une vidéo est important pour comprendre le contexte de la scène, ce qui est essentiel pour la détection. Par exemple, pour détecter un but, on peut s'appuyer non seulement sur l'image du ballon qui entre dans les filets, mais aussi sur le contexte de la scène, à savoir la joie de l'équipe qui marque et la déception de l'équipe qui encaisse le but.
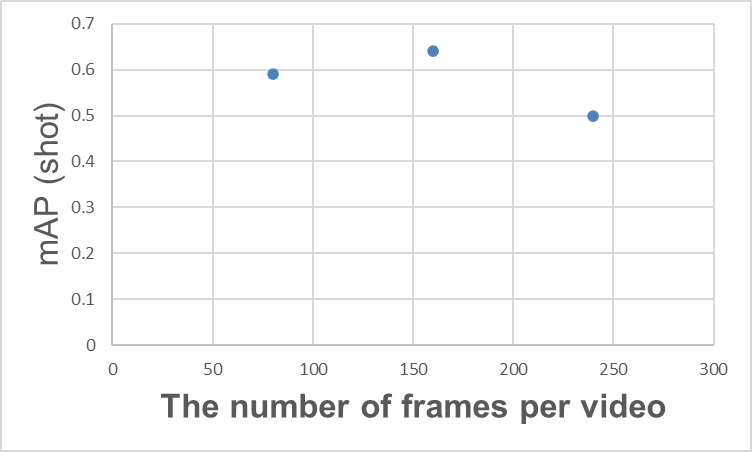
Relation entre le nombre d'images d'une vidéo et le mAP (shot)
On pourrait en conclure qu'il suffit d'augmenter le nombre d'images d'une vidéo, mais ce n'est pas nécessairement le cas. Par exemple, comme le montre le graphique ci-dessus, lorsque le nombre d'images d'une vidéo augmente, le mAP peut atteindre un certain niveau de saturation, puis diminuer. Des résultats similaires sont également mentionnés dans l'article sur T-DEED (tableau 6 (d)). Plusieurs raisons peuvent expliquer ce phénomène, mais l'une d'entre elles est que plus le nombre d'images augmente, plus les informations obtenues sont nombreuses, ce qui rend l'apprentissage plus difficile.
L'augmentation du nombre d'images par vidéo entraîne une augmentation de la quantité de calculs nécessaires à l'inférence. Il semble donc que l'ajustement du nombre d'images par vidéo en fonction des performances requises, de la vitesse d'inférence et du type d'actions ciblées contribue à améliorer les performances.
3.4 Essais et erreurs avec Playbox
3.4.1 Paramètre FPS fixe de T-DEED
Nous avons d'abord vérifié s'il était possible de sur-ajuster (suralimenter) une vidéo spécifique. Normalement, si le modèle est correctement construit, il devrait s'adapter parfaitement à une petite quantité de données. Cependant, le résultat a été un échec. Même en se concentrant sur une seule vidéo, la précision n'a pas augmenté du tout. L'enquête a révélé un point aveugle inattendu.
La cause était que le FPS (fréquence d'images par seconde) des vidéos était fixe dans TDEED, ce qui ne correspondait pas au FPS réel des vidéos Playbox. Dans la reconnaissance d'actions chronologiques, le décalage entre le temps réel (FPS) et le temps virtuel est fatal. Après avoir pris conscience de cette spécification, nous avons ajusté le paramètre FPS en fonction du format vidéo Playbox, ce qui a permis à l'apprentissage de progresser correctement.Le principe de base du débogage, qui consiste à « vérifier d'abord le surajustement à l'unité minimale », s'est avéré être le moyen le plus rapide de détecter une erreur fondamentale dans les spécifications.
3.4.2 Effets du modèle d'apprentissage préalable et de l'extension des données
Nous mentionnons également les éléments qui ont été testés pour améliorer la précision, mais qui se sont avérés inefficaces.
-
Fine-tuning du modèle pré-entraîné SoccerNet : nous avons affiné le modèle pré-entraîné avec Soccernet, mais cela n'a pas permis d'améliorer notablement la précision pour les vidéos Playbox utilisées dans le cadre de cette étude.
-
Application de l'augmentation des données (Data Augmentation) : nous avons essayé toutes les augmentations de données configurables dans TDEED, mais cela n'a eu pratiquement aucun effet sur les résultats.
4. Conclusion et perspectives d'avenir
Merci d'avoir lu jusqu'ici !
Points importants
- Action Spotting est une technologie qui détecte « quand » et « quoi » s'est produit.
- SoccerNet est un ensemble de données vidéo de diffusion bien connu, et diverses méthodes telles que T-DEED ont été proposées.
- Nous avons vérifié les performances d'Action Spotting sur des images filmées avec une caméra Playbox.
Perspectives d'avenir
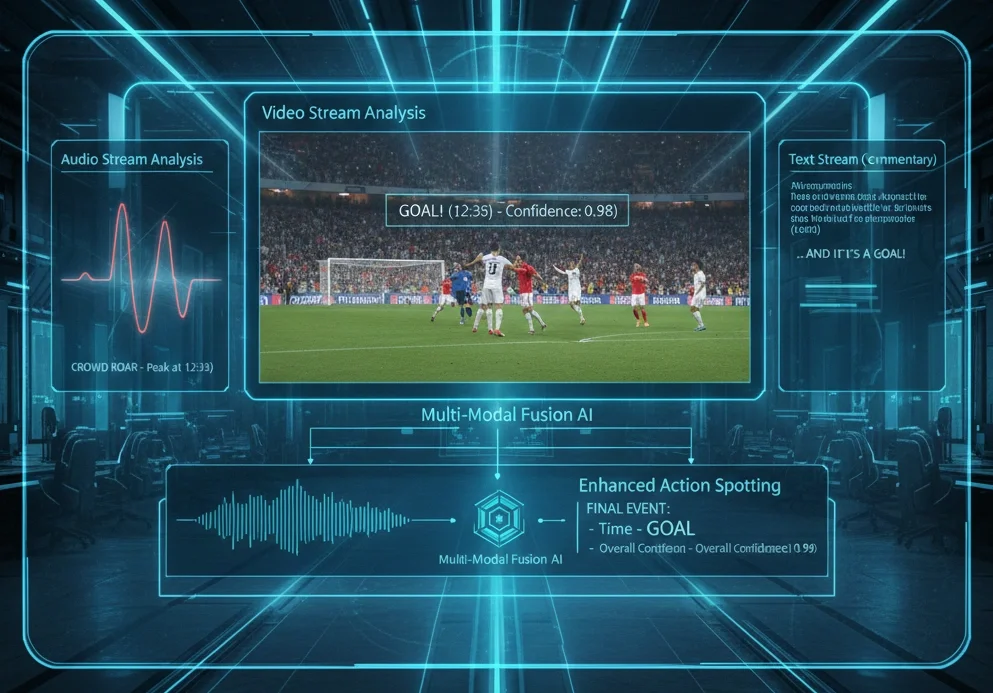
À l'avenir, on peut s'attendre à une amélioration des performances grâce à l'Action Spotting multimodal, qui combine non seulement des images, mais aussi du son (intensité des acclamations) et du texte (données de commentaires en direct).