Verpassen Sie nicht, was wann passiert ist: Action Spotting an vorderster Front und praktische Tipps aus der Playbox.
Hallo! Ich bin Chihiro Nakatani und absolviere derzeit ein Praktikum bei Playbox. Der Schwerpunkt meiner Doktorarbeit liegt auf der Erkennung menschlichen Verhaltens (CVIU2026・CVPR2024・ICCV2023).
Dieses Mal werde ich eine kurze Erklärung zu „Action Spotting” geben – einem Thema, das derzeit im Bereich der Sportanalyse große Aufmerksamkeit erregt – und dabei alles von den technischen Hintergründen bis hin zu den wichtigsten Punkten für die praktische Umsetzung behandeln.
Inhaltsverzeichnis
- Was ist Action Spotting?
- SoccerNet bei CVSports
- Einsatz von Action Spotting bei Playbox
- Zusammenfassung und Zukunftsaussichten
1. Was ist Action Spotting?
Während herkömmliche Videoklassifizierung darauf abzielt, „was im gesamten Video passiert“ zu identifizieren, besteht die Aufgabe von Action Spotting darin, „wann“ und „welche Aktion“ innerhalb eines langen Videos stattgefunden hat, genau zu bestimmen. In Sportaufnahmen sind Aktionen (Ereignisse) wie Schüsse flüchtige Ereignisse. Das Ziel von Action Spotting ist es, diese „augenblicklichen Ereignisse“ entlang der Zeitachse mit hoher Genauigkeit zu erkennen und ihre Zeitstempel anzugeben.
SoccerNet Beispiel für Action Spotting in Videos
Action Spotting kann in verschiedenen Bereichen eingesetzt werden, darunter die Erstellung von Highlight-Videos, taktische Analysen, die Bewertung von Spielern für das Scouting und die Einbindung von Fans.
2. Action Spotting bei CVSports
Wenn man über Sportanalysen spricht, kommt man nicht umhin, den SoccerNet-Datensatz und -Benchmark zu erwähnen. Der CVSports-Workshop bei CVPR, einer der führenden internationalen Konferenzen im Bereich Computer Vision, veranstaltet verschiedene Wettbewerbe, bei denen dieser Datensatz verwendet wird. Darüber hinaus wird es bei der kommenden CVSports (CVPR2026) im Juni einen Gastvortrag von Herrn Atom Scott, CEO von Playbox, geben. Bleiben Sie dran!
2.1 SoccerNet-Datensatz
Er umfasst Aufnahmen von über 500 Spielen, die aus den großen europäischen Ligen stammen. In den letzten Jahren wurde neben Action Spotting auch die Statuserkennung (GSR) – bei der die Rolle jedes Einzelnen (Feldspieler, Torwart, Schiedsrichter usw.) und Positionsinformationen identifiziert werden – als eine äußerst wichtige Technologie für die taktische Analyse und Spielbewertung weiterentwickelt. Playbox nimmt auch am GSR-Wettbewerb bei CVSports (CVPR2025) teil.
2.2 Annotationen für Action Spotting
SoccerNet definiert 17 Aktionsklassen als Erkennungsziele für Action Spotting. Die Zeitstempel, zu denen diese 17 Aktionsklassen auftreten, werden in jedem Video annotiert. Die Klassifizierung dieser 17 Klassen nach Aktionstyp und den für die Erkennung erforderlichen Merkmalen ergibt Folgendes:
[Schussbezogene Aktionen]
- Tor・Torschüsse・Fehlschüsse
- Wichtige Merkmale: „Ballflugbahn” und „Bewegung des Tornetzes”
[Kick-Aktionen]
- Indirekter Freistoß・Direkter Freistoß・Anstoß・Eckball・Klärung・Einwurf
- Wichtige Funktionen: „Ballposition“ und „Spieleraufstellung“
[Entscheidungsbezogene & Sonstige]
- Abseits, Elfmeter, Foul, Gelbe Karte, Rote Karte, Gelbe Karte → Rote Karte, Auswechslung, Ball im Aus
- Wichtige Merkmale: „Gesten des Schiedsrichters“ und „Detaillierte Bewegungsinformationen für bestimmte Spieler“
2.3 Bewertungsmetriken
Action Spotting bewertet anhand des mAP (Mean Average Precision) die Genauigkeit der Vorhersage, wann (Zeitstempel) die Zielaktion stattgefunden hat. Ein vorhergesagter Zeitstempel gilt als korrekt, wenn er innerhalb eines bestimmten Zeitfensters (innerhalb von δ Sekunden) der Grundwahrheit liegt. Anschließend wird für jede Klasse der AP (Average Precision) auf der Grundlage von Präzision und Recall berechnet.
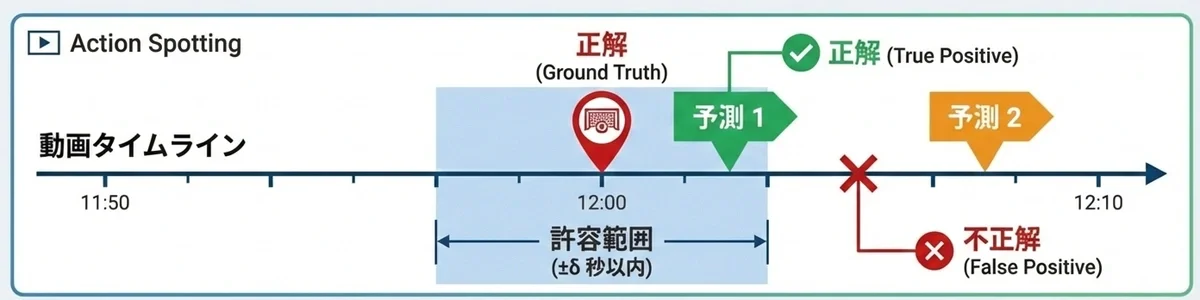
Erfolg/Misserfolg der Erkennungsergebnisse in Action Spotting
2.4 Basismodelle
T-DEED: Temporal-Discriminability Enhancer Encoder-Decoder for Precise Event Spotting in Sports Videos zeigt eine außergewöhnlich starke Leistung bei Action Spotting. Diese Methode, die auf der CVsports '24 vorgestellt wurde, erfasst zeitliche Merkmale aus Videos, die aus L-Frames bestehen, und erkennt gleichzeitig für jedes Frame, ob eine Aktion stattfindet und um welche Aktion es sich handelt.Wie das folgende Diagramm veranschaulicht, stellt die große Anzahl von Frames, in denen „keine Aktion stattfindet”, eine der Herausforderungen beim Training dar.
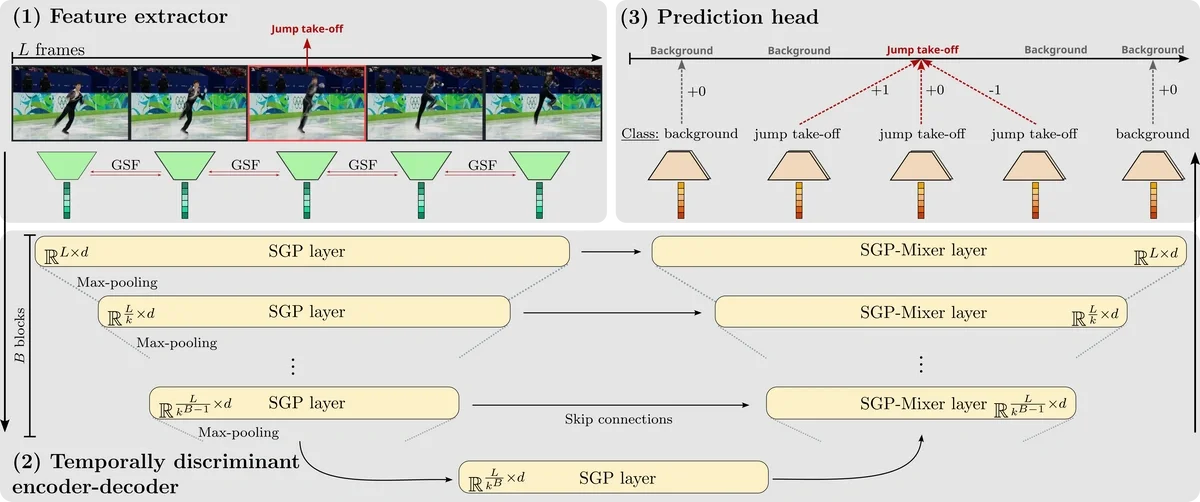
T-DEED-Übersichtsdiagramm (https://arturxe2.github.io/projects/T-DEED/)
Betrachtet man die Ergebnisse des Trainings von SoccerNet's Action Spotting unter Verwendung dieses T-DEED, so sieht man, dass der mAP bei etwa 60-80 liegt, was auf eine relativ hohe Leistung und erfolgreiche Erkennung hinweist.
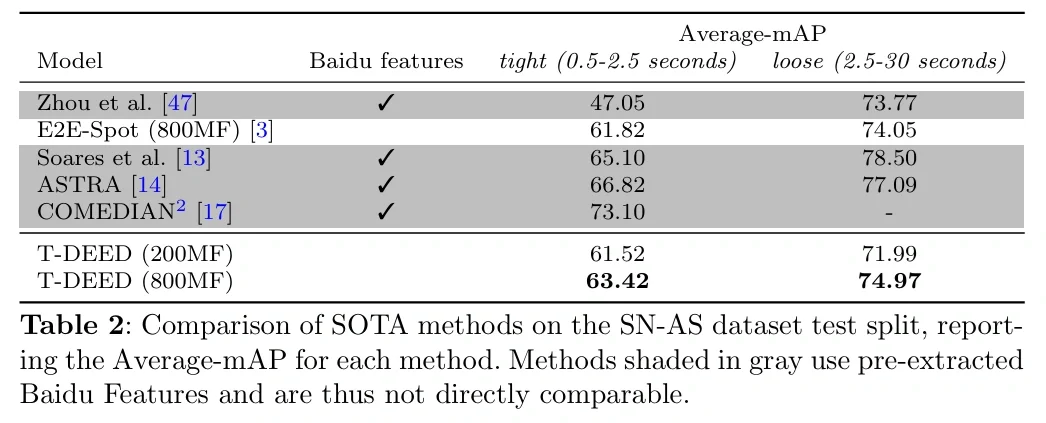
mAP für den SoccerNet-Datensatz (https://arturxe2.github.io/projects/T-DEED/)
Da es sich bei den SoccerNet-Videos jedoch um Fernsehaufnahmen handelt, sind die Aufnahmebedingungen zwischen den Videos ähnlich, was darauf hindeutet, dass das Training auch mit begrenzten Daten relativ einfach ist. Im nächsten Abschnitt wird daher ein tatsächlicher Trainingsfall mit einer Playbox-Kamera vorgestellt, von der erwartet wird, dass sie Aufnahmen in verschiedenen Umgebungen macht, die sich von denen von SoccerNet unterscheiden.
3. Action Spotting mit der Playbox-Kamera
Die Playbox-Kamera ist für Aufnahmen in unterschiedlichen Umgebungen konzipiert, was zu größeren Unterschieden in den Aufnahmebedingungen zwischen den Videos im Vergleich zu SoccerNet führt. In dieser Studie wurden die erforderliche Datenmenge und andere Faktoren für die Aktionserkennung anhand von Videos untersucht, die in solchen unterschiedlichen Umgebungen aufgenommen wurden.
3.1 Überblick über den Datensatz
Wir stellen die spezifischen Inhalte des in dieser Studie verwendeten Datensatzes vor.
3.1.1 Videodaten der Playbox-Kamera
Die mit der Playbox-Kamera aufgenommenen Bilder bewahren die Unmittelbarkeit der tatsächlichen Spiele und erfassen das gesamte Spielfeld oder bestimmte Spielzüge. Ein Beispiel für das tatsächliche Video ist unten zu sehen.
Beispiel für Aufnahmen der Playbox-Kamera
3.1.2 Aktionsklassen
Dieses Mal konzentrieren wir uns auf die folgenden sechs Klassen in einem Fußballspiel.
| Klassenname | Beschreibung |
| ck | Eckstoß |
| Anstoß | Anstoß |
| Tor | Torszene |
| Schuss | Schuss |
| FK | Freistoß |
| Strafstoß | Strafstoß |
3.1.3 Annotationsmethode
Die manuelle Annotation wurde von menschlichen Annotatoren durchgeführt. Jedes Video wurde Frame für Frame überprüft, wobei Zeitstempel für bestimmte Aktionen aufgezeichnet wurden (z. B. der Moment, in dem der Ball getreten wurde, der Moment, in dem er die Torlinie überquerte).
3.1.4 Datenskalierung
Das Gesamtvolumen der für die Analyse verwendeten Daten ist wie folgt.
-
Gesamtzahl der Videos: 345
-
Annotationseinheiten: Auftrittspunkte für die oben genannten sechs Klassen innerhalb jedes Videos
Mit diesen Datensätzen haben wir die Grundlage für die automatische Extraktion von Spielhighlights und die Generierung statistischer Daten aus Playbox-Kameraaufnahmen geschaffen.
3.2 Ergebnisse
Das Training mit 345 Videos ergab, dass „das System bei Spielzügen mit bestimmten Mustern außergewöhnlich gut funktioniert, bei plötzlichen Bewegungen jedoch noch Verbesserungspotenzial besteht“. Insbesondere Kick-offs und Standardsituationen werden mit relativ hoher Genauigkeit erkannt.
3.2.1 mAP-Ergebnisse
Zunächst untersuchen wir den mAP für jede Klasse.
| Klasse | mAP |
| Gesamtdurchschnitt | 0,43 |
| Start | 0,71 |
| Schuss | 0,59 |
| ck (Eckstoß) | 0,51 |
| FK (Freistoß) | 0,39 |
| Tor | 0,38 |
| Elfmeter (Strafstoß) | 0,00 |
3.2.2 Beobachtungen aus den Ergebnissen
-
Standardsituationen weisen eine hohe Präzision auf
kick off(0,71) undck(0,51). Diese profitierten wahrscheinlich davon, dass sie aufgrund ihres klaren Musters „Ausgangssituation mit einem stehenden Spieler” leichter zu erlernen waren. -
Die Schwierigkeit der Torerkennung
goal(0,38) ist eine komplexe Aktion, die zwei miteinander verflochtene Ereignisse umfasst: „einen Schuss ausführen“ und „dieser Schuss führt zu einem Tor“. Diese gegenseitige Abhängigkeit hat das Lernen wahrscheinlich erschwert.
3.2.3 Visualisierung der Inferenz-Ergebnisse (Video)
Bitte sehen Sie sich Videobeispiele für tatsächliche Schuss- und CK-Erkennungen an.
Schusserkennungsergebnisse in Aufnahmen der Playbox-Kamera
Ergebnisse der Erkennung von Konter-Schüssen in Aufnahmen der Playbox-Kamera
3.3 Detaillierte Analyse
3.3.1 Datenvolumen (Anzahl der Annotationen) und mAP
„Wie viele Annotationen sind erforderlich, um eine gute Genauigkeit zu erzielen?“ ist eine der am häufigsten gestellten Fragen. Zusammenfassend lässt sich sagen, dass eine Erhöhung der Anzahl der Videos (Annotationen) den mAP verbessert, aber ab einem bestimmten Punkt eine Sättigung eintritt. Die tatsächliche Anzahl der Videos und der mAP für die Shot-Klasse sind unten dargestellt und zeigen, dass die Effizienz der Genauigkeitsverbesserung mit zunehmender Anzahl von Videos abnimmt.
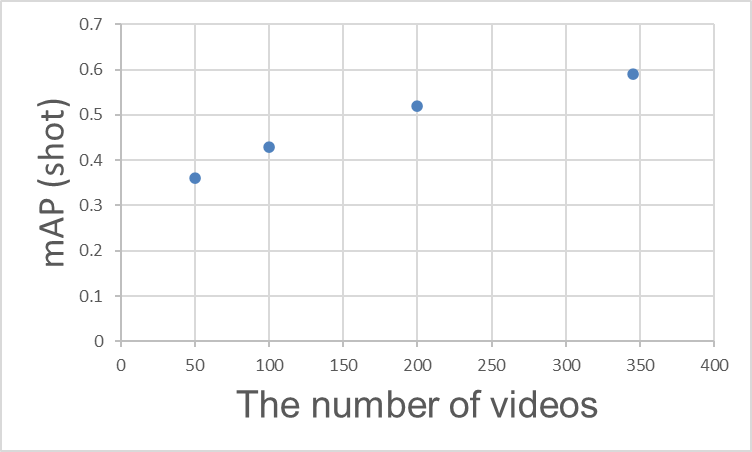
Zusammenhang zwischen der Anzahl der Trainingsvideos und mAP (Shot)
3.3.2 Bildrate (FPS) und mAP
Bei Action Spotting ist die Anzahl der Frames, aus denen ein Video besteht, entscheidend für das Verständnis des für die Erkennung wesentlichen Szenenkontexts. Beispielsweise sollte die Torerkennung idealerweise nicht nur das Bild des Balls, der das Netz erschüttert, sondern auch ergänzende Szenenkontexte wie die jubelnde Mannschaft oder die enttäuschte gegnerische Mannschaft berücksichtigen.
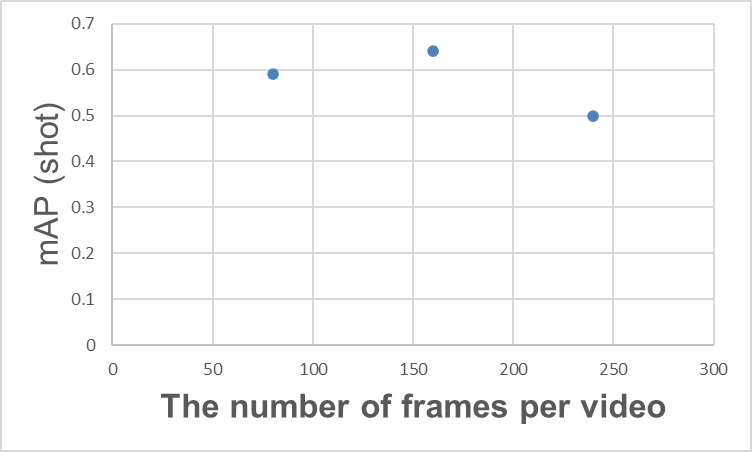
Beziehung zwischen der Anzahl der Frames pro Video und mAP (Schuss)
Man könnte zu dem Schluss kommen, dass „eine einfache Erhöhung der Anzahl der Frames pro Video ausreicht“ ... aber das ist nicht unbedingt der Fall. Wie in der obigen Grafik dargestellt, kann eine Erhöhung der Anzahl der Frames pro Video beispielsweise zu einer Sättigung des mAP an einem bestimmten Punkt führen, gefolgt von einem Rückgang des mAP danach. Ähnliche Ergebnisse sind in der T-DEED-Veröffentlichung dokumentiert (Tabelle 6 (d)). Dafür sind verschiedene Gründe denkbar; eine mögliche Ursache ist, dass eine Erhöhung der Anzahl der Frames zwar mehr Informationen liefert, aber auch das Lernen erschwert.
Eine Erhöhung der Anzahl der Frames pro Video erhöht auch die für die Inferenz erforderliche Rechenlast. Daher wird davon ausgegangen, dass eine Anpassung der Anzahl der Frames pro Video entsprechend der erforderlichen Leistung, der Inferenzgeschwindigkeit und der Art der angestrebten Aktion zur Leistungsverbesserung beiträgt.
3.4 Versuch und Irrtum mit Playbox
3.4.1 Feste FPS-Einstellung für T-DEED
Zunächst haben wir überprüft, ob bei einem bestimmten einzelnen Video eine Überanpassung auftreten kann. Wenn das Modell korrekt aufgebaut ist, sollte es normalerweise perfekt zu einer kleinen Datenmenge passen. Das Ergebnis war jedoch ein Fehlschlag. Selbst wenn man sich auf ein einzelnes Video konzentrierte, verbesserte sich die Genauigkeit überhaupt nicht. Die Untersuchung ergab einen unerwarteten blinden Fleck.
Die Ursache war, dass die FPS (Bildrate) des Videos intern in TDEED festgelegt war und von der inhärenten FPS der Playbox-Videos abwich. Bei der Erkennung aufeinanderfolgender Aktionen ist eine Diskrepanz im Zeitfluss (FPS) entscheidend. Als wir diese Spezifikation bemerkten, passten wir die FPS-Einstellung entsprechend an das Videoformat von Playbox an, und das Lernen verlief erfolgreich.Das grundlegende Debugging-Prinzip „zuerst die Überanpassung an der kleinsten Einheit überprüfen” erwies sich letztendlich als der direkteste Weg, um diesen grundlegenden Spezifikationsfehler zu identifizieren.
3.4.2 Auswirkung von vortrainierten Modellen und Datenanreicherung
Als Erkenntnisse dokumentieren wir auch Versuche zur Verbesserung der Genauigkeit, die sich als unwirksam erwiesen haben.
-
Feinabstimmung des vorab trainierten SoccerNet-Modells: Wir haben ein auf SoccerNet vorab trainiertes Modell feinabgestimmt, was jedoch zu keiner merklichen Verbesserung der Genauigkeit für die betreffenden Playbox-Videos führte.
-
Anwendung der Datenaugmentierung: Wir haben alle in TDEED konfigurierbaren Optionen zur Datenaugmentierung getestet, aber auch dies hatte nur geringe Auswirkungen auf die Ergebnisse.
4. Zusammenfassung und Zukunftsaussichten
Vielen Dank, dass Sie bis hierher gelesen haben!
Wichtige Punkte
- Action Spotting ist eine Technologie, die erkennt, „wann“ und „was“ passiert ist.
- SoccerNet ist ein bekannter Datensatz für Fernsehübertragungen, für den verschiedene Methoden vorgeschlagen wurden, darunter auch T-DEED.
- Wir haben die Leistung von Action Spotting anhand von Aufnahmen von Playbox-Kameras bewertet.
Zukunftsaussichten
Für die Zukunft werden weitere Leistungsverbesserungen durch multimodales Action Spotting erwartet, bei dem nicht nur Video, sondern auch Audio (Jubelstärke) und Text (Kommentardaten) kombiniert werden.